如何对混合日志进行自动化解析
本文分享自华为云社区《【AIOps】日志分析领域难题:如何对混合日志进行自动化解析?》,作者: DevAI。
AIOps智能运维,是指将AI应用于运维领域,基于已有的运维数据通过AI的方式来解决传统运维没办法解决的问题;本文聚焦在AIOps领域的日志解析子课题。现有的日志解析器 (log parser) 在实际生产应用时面临着两大局限:
一是现有日志解析器假定所有日志都是单行文本,但是实际生产环境中收集到的日志可能包含多行的日志消息(例如Java堆栈和Hadoop计数器),这会导致传统日志解析器逐行提取模版的解析范式无法适用于这些多行日志。二是传统日志解析器依赖固定解析规则,难以满足不同场景下的解析需求。为了解决这些问题,本文提出了一种全新的混合日志解析器:Hue。Hue是一种基于启发式解析树适用于复杂混合日志的日志解析方法。本文在三个混合日志数据集和十六个广泛使用的单行日志数据集上进行了综合评估,混合日志数据集包括真实的华为云线上云服务日志。结果显示Hue在混合日志和单行日志数据上都表现出了最优的解析能力。
1. 混合日志和解析任务介绍
本文定义了混合日志的消息类型包括单行的事件日志(Event Log)、具有清晰的行列结构的表格日志(Table Log)、以及具有跨行文本结构的文本日志(Text Log)。
- 事件日志(Event Log):事件日志是单行日志消息。事件日志记录服务或组件的操作或状态,包含日志头和消息内容。为了与现有单行日志解析任务中的定义保持一致,事件日志的模板由日志消息中的常量和表示变量的通配符组成。
- 表格日志(Table Log):表格日志是多行日志,包含一个表头、多行参数和潜在的表行。具有相同日志模板的表格日志具有相同的表列数和不同的行数,并且同一列中的token数据类型相同。由于表格日志的表头由区分不同表的关键信息(即列号和列类型)组成,因此表格日志的模板是表头,而表内容被视为解析后的日志消息中的参数。因此,对表格日志进行日志解析的目的是提取其表头,并将其表内容转换为参数。
- 文本日志(Text Log):文本日志是不属于“表格日志”类别的多行日志。文本日志以明文的形式记录系统事件之外的详细信息,如程序中的回溯调用堆栈,或以键值对的形式记录数据库内容等。文本日志广泛存在于Hadoop、Spark和MySQL等众多组件中。本文将文本日志的模板定义为几行保持不变的标记,例如traceback错误类型或消息中的键。因此,对文本日志进行日志解析的目标是从消息中提取这些行。
此外,本文同样定义了混合日志解析任务的目标是区分混合日志中的消息类型,并提取不同日志消息的公共部分作为日志模版。与传统日志解析相比,混合日志解析是一个更通用、覆盖面更广的研究问题,当日志中所有消息都是单行的事件日志时,混合日志解析任务退化为传统单行日志解析任务,即传统日志解析任务是混合日志解析任务的一个子集。混合日志解析任务如图中所示。

2. 一种全新的混合日志解析器:Hue
本文提出了一种全新的混合日志解析器Hue。Hue是一种无监督的在线日志解析器,它利用启发式解析树和高效的人工反馈机制,使其既能自动化地高效解析混合日志,也能根据使用者的需求反馈高精度地解析混合日志。具体而言,Hue首先通过聚合混合日志的相邻行的方式,再挖掘日志的行间特征,从而确定日志的消息类型;之后,Hue通过使用解析树的启发式规则,挖掘聚合后的日志行的行内特征,从而确定日志消息的具体模版。除全自动解析模式以外,Hue也允许根据使用者的反馈进行半自动的解析。Hue将自动识别可能具有多种解析结果的日志消息,并向用户抛出反馈请求,以及时修正解析过程。Hue的工作流程如图所示。

具体而言,Hue混合日志解析方法主要包括四步:
- 关键字铸造(Key Casting):现有的预处理策略难以处理可能包含表格日志和文本日志的混合日志,例如表格日志中只有变量的行,这些行会被现有的预处理策略全部删除或转换为相同的通配符,从而导致解析不准确。Hue采用了一种全新的预处理策略,称为关键字铸造(Key Casting),其主要思想是使用不同的通配符在预处理中更好地编码先验知识。Hue用空格分割一行,并根据通用的转换表将常用的作为变量的token转换为相应的通配符。
- 行聚合(Line Aggregating):为了正确解析混合日志,识别日志类型至关重要。直观上,使用行号来标识事件日志相对容易;但区分表格日志和文本日志是具有挑战性的,因为它们都具有多行结构。为了克服这个问题,本文提出了行聚合来区分表格日志和文本日志。表格日志中的相邻行往往表现出更高的相似性,而在文本日志中,尽管相邻行不太相似,但它们通常共享相同的缩进,因此,Hue通过对多行日志中的相邻行进行聚合,并根据相邻行的序列相似度和缩进数来识别日志类型。
- 模式提取(Pattern Extracting):传统的日志解析器通常使用完整的日志消息进行聚类,这在混合日志解析中效率很低,因为混合日志消息在扁平化后可能会非常长。此外,来自同一模板组的多行日志的行数可能相差很大,导致消息级聚类的准确性较低。为了应对这些挑战,Hue提出了模式提取方法,它利用从线聚合中获得的阻塞队列和日志类型来对具有相同模板的日志进行分组。
- 在线解析(Online Parsing):Hue进行在线解析时,会获取当前日志的模板,并更新每个日志组中过期的模板;同时通过引入引导式的更新机制,以增强具有模糊日志的日志文件的解析性能。
3. 效果评估
本文全面对比了Hue在混合日志和单行日志上的解析精度,也对比了Hue在全自动解析模式下和半自动(人工反馈)模式下的解析精度。本文在三个混合日志数据集(如Table 1中所示)和十六个广泛使用的单行日志数据集(如Table 4中所示)上对方法进行了综合评估。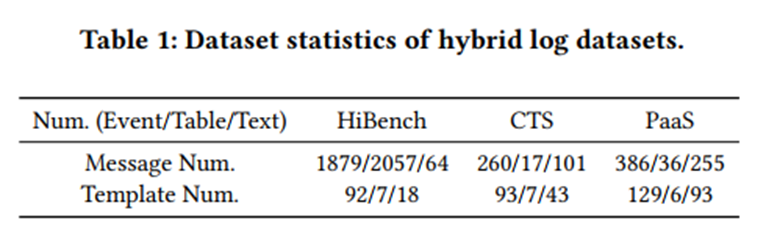
如Table 2和Table 3中所示,本文使用Group Accuracy(GA)和F1-Score上评估了Hue在全自动模式下的混合日志解析精度。考虑到Hue是第一个具备解析混合日志的解析器,且现有日志解析器无法解析混合日志,本文在测试其他解析器时将所有多行日志数据拉平为单行之后再对现有解析器进行评估。从图中可以看出,由于拉平过程破坏了多行日志的行间特征,导致现有解析器完全无法正常完成混合日志的解析。

本文也评估了Hue在传统的单行日志解析任务上的精度。如Table 4和Table 5所示,本文依然沿用Group Accuracy(GA)和F1-Score指标对Hue在全自动模式下的解析能力进行评估。结果显示即使没有引入任何人工反馈,Hue也能超越现有的日志解析器。
此外,本文评估了在允许使用人工反馈的前提下,Hue在混合日志和单行日志上的解析精度的提升能力。如Figure 11和Figure 12图中所示,Hue在正确的人工反馈的指导下,解析精度仍然能进一步提升。
4. 总结
本文来自华为云PaaS技术创新Lab和香港中文大学(深圳)贺品嘉教授团队合作项目成果产出,相关研究成果已被软件工程领域顶会FSE’2023(CCF A类)正式录用(论文题目:【Hue: A User-Adaptive Parser for Hybrid Logs】)。本文对混合日志和混合日志解析问题进行了深入研究,并形式化地定义了混合日志类型和混合日志解析任务的目标。本文提出了第一个可以对混合日志进行高效处理的解析器Hue。Hue是一种基于启发式解析树,能够精确解析复杂的混合日志的方法。Hue允许用户自行决定拒绝部分解析规则的更新,从而满足不同场景下的解析需求。本文在三个混合日志数据集和十六个广泛使用的单行日志数据集上对方法进行了综合评估,这些数据集既包括开源软件上的数据,也包括经过脱敏后真实的华为云线上云服务日志。结果显示Hue在混合日志和单行日志数据上都表现出了最优的解析能力。
文章来自 PaaS技术创新Lab,PaaS技术创新Lab隶属于华为云,致力于综合利用软件分析、数据挖掘、机器学习等技术,为软件研发人员提供下一代智能研发工具服务的核心引擎和智慧大脑。我们将聚焦软件工程领域硬核能力,不断构筑研发利器,持续交付高价值商业特性!加入我们,一起开创研发新“境界”!
PaaS技术创新Lab主页链接:https://www.huaweicloud.com/lab/paas/home.html
热门相关:索维托爱情故事 新闻幕后 山杏 理疗师与可爱的女运动员 爱人共有